The post Gif-making: an exercise in digital media archeology appeared first on &.
]]>
The gif is ubiquitous. And it’s a mess. A relic from the dial-up web, it was one of the first image formats on the web. It’s become an essential part of the language of online communication, and it’s become a form of art it own right, it’s even bleeding into other forms of media (see PBS Idea’s discussion of the gif aesthetic in music videos).
Let me ask the naive question, what is a gif? How are they encoded, created, inscribed and rendered by browsers? How can can they be taken apart? How can they be made?
Kittler claims “we do not speak language, but language speaks us – and we have to participate in such systems of language, which are not of our own making. [… T]he practices of language [take] place in the switches and relays, software and hardware, protocols and circuits of which our technical systems are made”. (Parikka 70)
To study the gif, I’ve chosen to approach it both as an engineering project as well as a scholarly one. I want to make a tool to study gifs. Consider Latour’s comments about engineers:
Engineers constantly shift out characters in other spaces and other times, devise positions for human and nonhuman users, break down competences that they then redistribute to many different actants, build complicate narrative programs and sub-programs that are evaluated and judged. (Johnson 309)
The building of this program (or any program) is to engage with this kind of engineering. The engineer conceptualizes actors, spaces, interactions – and then invites the user to participate in that system. Specifically, this tool is an attempt at a kind of media archaeology. I’m interested in cracking video open, and rendering manifest its inner workings.
[M]edia-archaeological theories are interested in going ‘under the hood’ to investigate the material diagrammatics and technologies of how culture is being mediatically stored and transmitted. (Parikka 65)
There are a number of tools that are readily available for creating and viewing gifs. Some even run in the browser (giphy), and many image and video-editing programs can export as gifs (Photoshop, GIMP). If my interest was in simply making a short, embeddable, looping video – these would serve me well.
However, I’m interested in going under the hood, and that means I’m going to have to step away from platforms. It’s not going to be enough to use a set of tools that were developed outside of academia. After all, there are a number of free and open tools that encourage exactly this kind of study.
In relation to our discussion of doors, consider the lock. Specifically, digital locks: DRM. How are we going to do scholarship on media if we are alienated from the tools that produce and embed that media?
Here’s a list of the tools I’m using, along with their licenses:
– Programming: emacs, the text editor whose role in the development of free software is important (Richard Stallman founded the Free Software movement in the wake of a dispute over who owned it). It uses the GPL-3.0 License
– Operating system: linux which uses the GPL-2.0
– Version control: git which also uses GPL-2.0
– Programming language – Lua uses the MIT license
– Framework (for graphics rendering): love uses the zlib/libpng license
– video encoding/decoding – FFmpeg – which exists in a legal gray area (it can decode so many proprietary video formats)
Why the attention to licenses? For one, there is an incredible range of diversity in software licenses. Some of the licenses above are more permissive than others. Particularly, the GPL-3 license requires that if any part of it is used in another program, that other program must also be licensed under the GPL-3. It has been described as virus-like:
In the views of Richard Stallman, Mundie’s metaphor of a “virus” is wrong as software under the GPL does not “attack” or “infect” other software. Stallman believes that comparing the GPL to a virus is an extremely unfriendly thing to say, and that a better metaphor for software under the GPL would be a spider plant: If one takes a piece of it and puts it somewhere else, it grows there too. (Wikipedia)
By using free software, it becomes much easier to “inscribe the act of investigation into the critical work”. (Drucker) Not only because of the way free software licenses resist DRM, but also in that they encourage the kind of remixing and disassembly that’s essential to the critical project:
“When we call software ‘free,’ we mean that it respects the users’ essential freedoms: the freedom to run it, to study and change it, and to redistribute copies with or without changes. […] In a world of digital sounds, images, and words, free software becomes increasingly essential for freedom in general. (FSF)
All of the above software is free.
With a set of tools that I felt were adequately open, here were my guiding principles:
- the practical :: design a simple interface for exploring and creating looping video
- the scholarly :: document the design methodology
So let’s begin.
Once I have a video, I can use ffprobe (a command line tool that’s part of the FFmpeg project)
to get the frame count, frames per second, and resolution of the video. The first step in extracting frames from a video is to choose the time in the video to export frames from.
“We need to be doing user interface design” (Drucker)
To choose the time, I began with a simple slider. The indicator shows the time in seconds:
After selecting a time in the video to load, the program exports ten seconds of frames into png files. The image data from those files is then loaded into the program, where I can display it.
This is a good example of one of the difficulties in trying to program something that uses different processes simultaneously:
I needed to export individual frames from the source video (external process: FFmpeg)
As well as import each of those frames’ image data (internal process: love)
Modern computers have multiple processing units that can be assigned specific tasks (threads). I like the imagery of the word. It gestures towards the origins of computing as a form of weaving (Jaquard looms). By exporting video in one thread, and importing them in another I allowed the program to continue exporting frames while it simultaneously imported the image data.
With the image data accessible to the program, the next step is to navigate through those images. There were two modes of navigation I wanted to implement:
looping playback – the black marker shows the position of the playback
mouse navigation – when the cursor is over the timeline, the frame follows the cursor
this gif illustrates both:

Now that I can navigate through the video, I need to be able to create a loop. A loop necessitates two points in time, so how can I demarcate them and the space between them? There are all kinds of conceptual problems that I ran into here. To enumerate some of them:
What happens when the second point is moved before the first
How to designate which marker is selected when two are overlapping?
Which marker is moved when the timeline is clicked?
I decided to introduce the concept of selection, so that when the timeline is clicked, two markers are created: one on the location that was clicked, and the other is selected and dragged with the mouse until it’s clicked again at another location and the loop is completed.
I’ve illustrated it here:

This last step was difficult, particularly because it meant that each step of creating the loop markers and designating the loop playback period meant a conversion between three axes:
– position of the markers on the timeline (pixels)
– position of the frame in the loop (frames per pixel)
– position of the frame in time (frames per second)
The math is relatively simple to convert from one axis to another, but I found it difficult to juggle the abstractions well enough to put them in relation to each other.
“The easier something is to use, the more work to produce it” (Drucker 34:05)
I felt it keenly in developing this program. I built it around an extremely simple use case, and yet I found it impossible to reason about this object without invoking very specific notions of space and time.
If there’s some trace of a knowledge model in how I approached this project, it’s probably the following: there is an ecology of software. An ecology in the sense that Jane Bennett describes in her discussion of Spinoza’s natura naturans: “a materiality that is always in the process of reinventing itself”.
There’s no guarantee that any of the tools I used to build this project will continue to be maintained – or that they will continue to work with eachother. That’s the nature of software development, it’s in constant reinvention.
There’s plenty more to be with this project:
– make it compatible with OSX and Windows
– create an interface for selecting a source file
– extract, loop and export audio
I feel as though I’ve only just scratched the surface of the this media – and I’m aware that there’s probably not much interest in the programmatic side of the project, nevertheless, I’ve put a link up to the program here, where it will be updated as I continue to work on it.
The hidden cost of free software is learning how to use it. Knowing how to learn new software is a privilege, that’s why I feel it’s so necessary for scholars in the digital humanities to be open about their interface design methodologies.
Works Cited
Bennett, Jane. “The Force of Things: Steps toward an Ecology of Matter.” Political Theory 32.3 (2004): 347-72. Print.
Drucker, Johanna. “Digital Humanities from Speculative to Skeptical.” Concordia University, Montreal. 9 Oct. 2015. Web. <http://www.mediahistoryresearch.com/digital-humanities-from-speculative-to-skeptical/>.
“The Free Software Definition – GNU Project – Free Software Foundation (FSF).” The GNU Operating System. N.p., n.d. Web. 21 Oct. 2015.
Johnson, Jim. “Mixing Humans and Nonhumans Together: The Sociology of a Door-Closer.” Social Problems 35.3 (1988): 298-310. Print.
Parikka, Jussi. What Is Media Archaeology? Cambridge, UK: Polity, 2012. Print.
“Overwhelming and Collective Murder.” YouTube. YouTube, n.d. Web. 21 Oct. 2015. <https://www.youtube.com/watch?v=ze9-ARjL-ZA>.
“GNU General Public License.” Https://en.wikipedia.org/wiki/GNU_General_Public_License#cite_note-114. N.p., n.d. Web. 21 Oct. 2015.
The post Gif-making: an exercise in digital media archeology appeared first on &.
]]>The post Big Data and a Metallica Database appeared first on &.
]]>For this probe I chose to shift disciplines from my commitment to English literary studies to one – what I would call one of my primary musical passions – with which I have never engaged in any formal examination. The extent to which I chose to explore, categorize, and quantify my interest in Metallica is without a doubt a reflection of my juvenile state of mind, and on a more prominent level, perhaps reflects the degree to which I lack any serious creative potential as a graduate student. Despite my questionable mind frame, I am nevertheless approaching this task with a lot of passion and dedication because Metallica is quite frankly one of the only bands to which I have remained committed from the first time I heard their music. This motivation hardly provides relevant justification for making Metallica the object of my examination; however, my connection with this music serves as a useful analogy in terms of the way that I understand big data and shifting research standards in the humanities.
I first heard a Metallica song when I was fourteen years old and 12 years later I still occasionally listen to their tracks. In the early days of my love of Metallica I purchased all of their albums in CD format, while I likewise purchased as many of their concert videos that I could afford. For additional live performances in the form of either audio or video files, I would use sharing applications such as Bearshare and later Kazaa to get as much of their music and concert footage as I possible could. I recall waiting days for rare videos that lacked substantial support to download, and I repeated this waiting process numerous times for the sake of experiencing more and more Metallica. Beyond their official releases, my perception of the band’s catalogue of music and videos gradually became filtered through what I could access on these sharing platforms. The corpus with which I would work remained contingent upon what I could find on these applications. In total, I downloaded hundreds of live tracks and videos. I cannot provide an exact figure because I no longer have access to the computer on which I downloaded all of those files, and I did not back up those files on an external hard drive. What a fool I was. Nevertheless, there was a time when I believed that I had accessed every possible live track and performance that a Metallica fan could possibly obtain. Again, what I fool I was…
If you enter Metallica in Youtube’s search field, you will see that there are currently over nine million related videos on this platform alone. There is not enough time in a human life for a person to watch and analyze all of these videos…
In light of this particularly daunting bit of information, I chose to draw all of the video files that I recall downloading and watching at one time or another from the millions of video files on Youtube. I categorized them in a personal database so that I may have a record of the clips that I have viewed in the past twelve years. To create my database I used Zotero which – from what I understand – is a research tool that synchronizes directly with Firefox and Chrome browsers, and according to this software, I have viewed three hundred and seventeen different Metallica videos. However, these are the only ones that I can recall watching and I am sure that if I were to explore further into the depths of Youtube I could easily add another hundred to the collection.

Although this database helped create a comprehensible data set from which I could then categorize and interpret this collection, I was approaching this task according to my conditioning as a student of literature. As jockers states: “The literary scholar of the twenty-first century can no longer be content with anecdotal evidence, with random ‘things’ gathered from a few, even ‘representative,’ texts” (8). My approach to this database did not gravitate beyond what a ‘textual’ read would enable when I first examined the corpus, and I remained content in my traditional approach of which Jockers warns. Initially, I would argue based on the performance footage that I acquired that Metallica’s Justice album and tour indicates their alcohol and cocaine fueled critique of contemporary economic practices in the U.S., the perpetual destruction of social and personal relations due to warfare, and the alienated self in relation to a deteriorating national environment, while the album likewise indicates the bands internal power dynamics due to the record’s mastering process and their adjustments to their new bass player. This type of assessment represents what we would typically do as literature students: collect of set of information, interpret it in relation to its content and related texts, and draw a set of conclusions based on our examinations. Yet, like Jockers claims, “the literary researcher must embrace new, and largely computational, ways of gathering evidence. […] Today’s student of literature must be adept at reading and gathering evidence from individual texts and equally adept at accessing and mining digital-text repositories” (9). Consequently, although I engaged with a digital medium in my analysis, I did not gravitate beyond gathering evidence and making claims based on specific samples of a larger whole. In fact, like he goes on the suggest, “The very object of analysis shifts from looking at the individual occurrences of a feature in context to looking at the trends and patterns of that feature aggregated over an entire corpus.” (25). The potential for new scholarship through this reoriented approach led me to reconsider my initial angle on my database, and I subsequently attempted to utilize one of the tools that is specified on our syllabus for this week as a new approach to my corpus.
I consulted Graham, Milligan, and Weingart’s online text The Historian’s Macroscope: Big Digital History in which they identify (among many other things) data visualization in the form of word clouds as an effective first step when working with a large dataset and mining for information (to use Jocker’s analogy). However, as Underwood defines in “Where to start with text mining,” “There are two kinds of obstacles [that we confront when text mining]: getting the data you need, and getting the digital skills you need.” Fortunately, I had the data, but was skeptical of my digital skills when endeavoring to utilize a word cloud. Fortunately, the use of word clouds on Wordle.net is rather basic and user friendly and I attempted to produce a word cloud based on the lyric content of a collection of Metallica songs from my database. Although I was eager to produce this visualization, my Firefox was in need of an updated plug-in in order to produce the word cloud. When I attempted to install the new plug-in, my Firefox crashed and I can no longer open it since the “identity of the developer cannot be confirmed’ when I attempt to initiate the browser. I am sure that I would have been able to produce a rather interesting word cloud had I not encountered this technical issue (and had more tech knowledge to overcome this problem), but regardless of this minor conundrum, the point of exploring a word cloud was to pursue an avenue of research that engages with big data and pushes research practices into new avenues.
Again, as Jockers states, “Broad attempts to generalize about a period or about a genre by reading and synthesizing a series of texts are just another sort of microanalysis. This is simply close reading, selective sampling, of multiple ‘cases’; individual texts are digested, and then generalizations are drawn. It remains largely qualitative approach” (25). The intersection between qualitative approaches which are much more familiar to my current research practices, and the potential for alternative research avenues according to what Underwood and Graham, Miligan, and Weingart discuss, perhaps lends some credibility to what I have attempted to pursue, however mundane my work with this database may be. A typical qualitative approach has its limitations according to the model that I followed, although the potential for nuance within a synthesized method between what Jocker’s identifies as macro and micro scales through his economics analogy introduces a rich environment for divers scholarship.
The purpose of this exercise that I outlined for myself was simply to disrupt something familiar and what I assumed to be understandable. This database endeavor was a stretch from my initial downloading practices as a fourteen year old Metallica fan, and I find it rather intriguing to see how my experience of this music shifts according to a new digital framework that enables different – perhaps distant – readings of this band’s material. Granted, I cannot say that I have an entirely new outlook on their music, or that these exercises have opened up a new way to engage with their material. In fact I am wondering how this exercise has contributed anything valid at all. To be honest, I have thought about this band enough and I am eager to move on to something else, but this exercise has, first and foremost, reinforced the dynamics between a typical qualitative approach to a given object and the potential to expand a reading along avenues that redefine potential scholarship. With ever-growing datasets that seem far too overwhelming to approach in a scholarly context, at the very least there a tools to help quantify and engage with materials that would ordinarily seem far too broad and obscure according to my skill sets. So there are over nine million Metallica videos on Youtube…I think I will leave it at that.
Starting with a familiar dataset helped me interpret how big data operates according to the parameters that I set for my particular project. I can honestly say that I still do not know where this will lead me in my own research as a literature student, but the shift towards these new standards undoubtedly now feels palpable and has reoriented the familiar. Will big data and text mining approaches significantly impact my current practices in the near future? Of this I am uncertain, but I am open for the potential…
And if anyone can explain to me how this Probe is not a Bootcamp, then I would be very grateful!
Works Cited
Jockers, Matthew A. “Revolution,” “Tradition,” “Macroanalysis.” Macroanalysis: Digital Methods for Literary History. Urbana: University of Illinois Press, 2013. 1-32.
Underwood, Ted. “Where to Start with Text Mining.” The Stone and the Shell. August 14, 2012. http://tedunderwood.com/2012/08/14/where-to-start-with-text-mining/
Graham, S., Milligan, I., Weingart, S. “Topic Modeling By Hand.” http://www.themacroscope.org/?page_id=47
The post Big Data and a Metallica Database appeared first on &.
]]>The post Digital Overabundance; or, The Problem of Tweeting Poems appeared first on &.
]]>I have a complex and difficult relationship with Twitter.
No other content strategy strategy or social media platform has done more for me. My feed has gotten me an agent and several jobs; it’s connected to to innumerable people who have become friends and colleagues, collaborators and co-conspirators. It’s gotten me in the newspaper for swearing, repeatedly.
For example, David Gilmour gave a disastrous interview with Emily M. Keeler in Hazlitt, where some things he said included:
I’m not interested in teaching books by women. Virginia Woolf is the only writer that interests me as a woman writer, so I do teach one of her short stories. But once again, when I was given this job I said I would only teach the people that I truly, truly love. Unfortunately, none of those happen to be Chinese, or women. Except for Virginia Woolf. And when I tried to teach Virginia Woolf, she’s too sophisticated, even for a third-year class. Usually at the beginning of the semester a hand shoots up and someone asks why there aren’t any women writers in the course. I say I don’t love women writers enough to teach them, if you want women writers go down the hall. What I teach is guys. Serious heterosexual guys. F. Scott Fitzgerald, Chekhov, Tolstoy. Real guy-guys. Henry Miller. Philip Roth.
So I tweeted a bunch of things in response, including:

The National Post, in this article, characterized this and my other tweets as follows: “Toronto-based writer and critic Natalie Zed responded to Mr. Gilmour’s interview with an afternoon’s worth of insults and obscenities.” Presumably without actually reading this or my other tweets, Naomi Lakritz at the Calgary Herald wrote a whole article about how I’m “helping to perpetuate the troll culture that flourishes online.”
Why, just yesterday, Adam Baldwin called me a Social Justice Warrior. What more could a person who lives on the internet ask for.
I’m also fairly certain Twitter is destroying me as a writer.
* * *
At the beginning of “It Looks Like You’re Writing A Letter: Microsoft word, Matthew Fuller describes a scene in which a writer, working at a word processor, is wired to a bomb; as soon as the writer is no longer forming grammatically sound sentences at a quick enough rate, the bomb goes off. That explosion is inevitable.
Being on Twitter is like being hooked up to that explosive device, only rather than being blown to smithereens, the risk is the loss of your audience. Like a crown gathered to gawk at a car accident, your readership disperses quickly on the platform if you’re no longer as active, as funny, as engaging as you once were. It’s not enough to build a reputation for providing commentary on a curated list of topics; you have to stick to the rules and the strategy you’ve build, or your readership wanders away. It’s the publishing cycle at its most drastically compressed: instant gratification, or abandonment.
It’s not the ever-present hum of this threat, that your readers might just up and leave you at a moment’s notice, that bothers me about Twitter; it’s what all those tweets are adding up to any way. It’s what’s being constructed, other than a personal brand or the idea of a platform. I’m apparently teetering on the edge of my 55,000th tweet, 7,700,00 characters thrown out into the universe. Those words and phrases and ideas haven’t been building books, they’ve been part of a feed, something that scrolls past and disappears.
In the first section of his piece, Fuller notes that “all word processing programs exist at the threshold between the public world of the document and those of the user. These worlds may be subject to non-disclosure agreements; readying for publication; hype into new domains of intensity or dumbness; subject to technical codes of practice or house style; meeting or skirting round deadlines; weedling or speeding.” Twitter exists at an intersection that is even more public, and, like Word, also has the potential to “detour or expand these drives, norms and codes in writing” in sometimes catastrophic ways.
* * *
Three things make Twitter wonderful: constraint, community and ephemerality.
These three ideas correspond, roughly to three concepts that Alan Liu explores in “Transcendental Data: Toward a Cultural History and Aesthetics of the New Encoded Discourse”: content management, transmission management and consumption management (56-57). The content is managed via the constraint that it is placed under via the strict character limit; it is transmitted to an ever-changing, mercurial and deeply interactive audience; and it is consumed in a way that highlights both the intensity and impermanence of the platform. It is perhaps the ephemerality of Twitter, and the way this effects the way writing on Twitter is consumed, that is the most important point here; a central mechanic of the way the platform works is how quickly things appear, attract attention, and then sink back into the massive flow of content.
Originally conceived of as a micro-blogging platform, one of the great strengths of the medium is how innately restricted it is. With only 140 characters to express yourself, everything is clipped and contained, the most meanings squeezed into the smallest space. It’s still possible to go on a tear, of course, to rant, but there can be no wall of text, only a broken chain, each unit to be engaged with individually or ignored, retweeted in entirety or cherry picked. It forces you to communicate in a very specific way, distilled and heightened, a series of love letters on post-it notes.
While there is pleasure in creating in the pleasant containment of the medium, the real appeal of Twitter is the community it gives you access to, and with it the intoxicating allure of instant feedback. It’s like having a laugh track kick in the moment you say something funny. Thee’s an instant response to anything you say: a deluge of support or derision, and even the ominous silence is a kind of feedback. Each tweet has potential, even from someone with a small or highly curated following; a particularly clever though, a few strategic boosts and that lonely line tossed off into the world can accrue hundreds and even thousands of retweets and responses. Anyone can be a trending topic, representing a kind of virality that provides a variation on the idea of fifteen minutes of fame. But it’s not the potential scale of the audience that truly seductive, but how immediately that audience, of any size, responds. It’s the instantaneousness of the feedback (and the brevity of any content’s life span on the platform) that is appealing. Even with the incredibly compressed cycle of content online, the half life of blog posts and articles is unquestionably longer. For instance, I was interviewed by Feministing about pathologizing kink in 2012, and suddenly it made the front page of Metafilter in August.
Twitter trades the potential for this slightly longer content cycle for the ability to be read, responded to, critiqued or attacked immediately. Feedback is not something you need to wait for; it’s all live and all happening in real time. This immediacy also has some dangerous and hilarious consequences. For example, when PR executive Justine Sacco tweeted something terribly racist and then got on a plane, the online world erupted while she was obliviously offline. Articles were written; the hashtag #hasjustinelandedyet started to trend; Sacco was fired. An entire news cycle rose and fell before she disembarked to find herself, for a brief moment, a villain on the Internet.
There is a flip side to the speed and immediacy of engagement on Twitter, and that is its ephemerality. Things disappear into the flow of your feed, and even the most engaged and devoted audience is going to miss most of what you write. There are ways to extend the life of tweets of course — Storify for longer conversations, screen shots for tweets you suspect might be soon deleted — all of which attempt to put individual together into larger narratives, to map the conversations that break off and build, rhisomatically, off of a single tweet. Despite these tools, tweets represent content that is, for the most part, meant to be lost.
There’s something about this aspect of Twitter — the way the form blithely does not care that so much of the content it generates will, by nature of the way the mechanism works, be missed entirely — that reminds me of Fuller’s statement in the “Word Processing” section of his article that “effective human-machine integration required that people and machines be comprehended in similar terms so that human-machine systems could be engineered to maximise the performance of both kinds of component.” It’s not important that the content is read; it is important that it is generated. Where Twitter and word differ profoundly, however, is that rather than the “end point” of Word that Fuller points to, when “every possible document will be ready for production by the choice of correct template and the ticking of the necessary thousands of variable boxes,” Twitter strips down the tools of composition to an empty box to fill with words, or the means to copy content, to replicate content and help it spread via retweets. Virus vs. Bacteria.
* * *
So how the hell is Twitter, not as a platform but as an actual medium, useful for writing, and worth examining as a tool for building digital texts? Firstly, it teaches us that our work is disposable, and this is immensely freeing. The impermanence of the form helps erode whatever concepts of ownership over our work and ideas we might cling to, and also helps diminish the notion that every thought we have is a precious gold nugget that deserves to be held up and polished. It reinforces the truth that we are all idea machines, and even if we give every one of our ideas away, we’ll keep on having new ones every moment.
This is also whyI worry that Twitter is making me, in particular, a different and possibly less effective writer: by encouraging me to throw everything away, I may also be refusing to hold on to the raw ore that does deserve refining. The key, I think, is to turn Twitter into a tool that aids in the refinement, in the sorting of raw material, the sieve through which we pass our ideas to see what is the most valuable. In seeing how the vast and amorphous audience we accrue responds to each granular thought, we can test out what works and what doesn’t. We take the lines and stories and ideas that get the best responses and work with them, make them better; we can treat our followers as beta testers for our writing.
Even if we regard twitter as a tool for creating digital texts, engaging in this process unquestionably changes the writing that emerges from it. Twitter as a medium has given rise to its own genres, perhaps the most recognizable of which is the phenomenon of the livetweet. Every event and encounter has the potential to become breaking online news in this way. Livetweets can range from the typical format of attending any kind of event and relaying it via quotations, observations, commentary, like live reviews in real time, to accidentally overhearing and narrativizing breakups in public places, Eavesdropping 2.0.
Beyond the livetweet, there are self-contained incarnations of Twitter that aren’t intended for a life outside the platform, and also aren’t rooted in non-fiction. Some of these are pieces of absurdist beauty, like Horse ebooks, which dismantled spam and affiliate marketing into broken gems of text; some break other texts by fragmenting them into the constraint of the medium, like Vanessa Place‘s retyping of the entirety of Gone With The Wind; some are just wondrous strange, like Kimmy Waters’ feed (a/k/a @arealliveghost). [What Would Twitter Do?, an interview series by Sheila Heti for The Believer, is a great source for some of the most compelling uses for Twitter currently running]. These feeds tackle the problem that Liu touches on when he writes, “consider the problem of sending a poem over the internet to a distant computer without knowing exactly what program will receive it, the nature of the processing or display technologies at the other end, or even the remote user’s purpose” (52). While each project, or feed, or series of eruptions is profoundly different in its method and means, the one thing all these accounts have in common is that the successful ones are the weirdest, the most broken.
* * *
I’m honestly not sure I’ve succeeded in doing anything here but having feelings about Twitter, in the context of this week’s readings. Perhaps at best I’ve puzzled out that is stands at the centre of a Venn diagram between word processor, social media platform, tool and transmitter, something akin to what Liu calls “The tight, tense marriage between content and materiality/form” (74). Whether it’s being used as a box to fit words in or one to stand on, it’s a tool that frustrates me, and one I don’t quite knowhow to use properly yet, but will continue to bang my head against.
Works Cited
Baldwin, Adam (@AdamBaldwin). “In which @CBCCommunity weighs in with #SJW’s false #Gamergate narrative: https://archive.today/iLrBr #WomenAgainstFeminism #NotYourShield.” 1 October 2014, 2:48 pm. Tweet.
Dusenbery, Maya. “A Conversation About Kink with Natalie Zina Walschots.” Feministing.
May 9, 2012. <http://feministing.com/2012/05/09/a-conversation-about-kink-with-natalie-zina-walschots/>
Fuller, Matthew. “It Looks Like You’re Writing A Letter: Microsoft Word.” Nettime.org. September 5, 2000. <http://www.nettime.org/Lists-Archives/nettime-l-0009/msg00040.html>
Hopper, Tristin and Mark Medley. “David Gilmour now the centre of literary firestorm for syllabus stock only with ‘serious heterosexual guys.’” The National Post. September 26, 2013. <http://arts.nationalpost.com/2013/09/26/david-gilmour-now-the-centre-of-literary-firestorm-for-syllabus-stock-only-with-serious-heterosexual-guys/>
Keeler, Emily M. “David Gilmour on Building Strong Stomachs.” Hazlitt. September 25, 2013. <http://penguinrandomhouse.ca/hazlitt/blog/david-gilmour-building-strong-stomachs>
Lakritz, Naomi. “Throw The Book At Trolls Who Attacked U of T Professor.” The Calgary Herald. September 29, 2013. <http://www.calgaryherald.com/opinion/op-ed/Lakritz+Throw+book+trolls+attacked+instructor/8969954/story.html>
Liu, Alan. “Transcendental Data: Toward A Cultural History and Aesthetics of the New Encoded Discourse.” Critical Inquiry 31 (Autumn 2004): 49-84.
Nisen, Max. “IAC PR Director Lands In South Africa After Racist Tweet, And It’s A Mess.” Business Insider. December 21, 2013. <http://www.businessinsider.com/justine-sacco-landing-live-tweeting-2013-12#ixzz3EyVMA3RZ>
Walschots, Natalie Zina (@NatalieZed). “The spirit of Virgina Woolf tucks David Gilmour in every night, pressing a kiss to his brow to protect him from all the other women.” 25 September 2013, 11:43 am. Tweet.
The post Digital Overabundance; or, The Problem of Tweeting Poems appeared first on &.
]]>The post Google Translate: Glitch Art and Deformance Methods appeared first on &.
]]>Probe * Nov 21st
“Dominate the dream of freedom due to the translation, materialized, reduce A normative struggle, new analysis focuses on what we call the transfiguration seems Emerging. This could significantly change the way through the public decision-making Close to the regime of recognition. No one claimed that schools have been decisively This concept covers the terrain. Even if we see the development of scholars, it is doubtful analysis protocols circulation and transfiguration understanding Replace the meaning and translation tools to understand they are doing Or so. However, the entire work, could not be more different in style, tone, Content and discipline, we see the development of new technologies catch Mapping function, not meaning as foreground figure Public culture technology Public Forms Coordination and figurating machine, the main component is not Situated in the play signifier and signified but functional indexicality Imitation (iconicity)…”
– Gaonkar & Povinelli Technologies of Public Forms: Circulation, Transfiguration, Recognition. Translated with Google Translate, 394[i]
Just when I was about to enter high school, my home state of Minnesota began one of the state’s first Chinese language programs. I jumped at the chance. While French and Spanish were great options, they had nothing to do with my personal history; Chinese was a way, I thought, to actualize a classic teenage yearning to ‘get in touch with my roots’. Turns out it was torture.
As many of you probably know, written Chinese is a non-phonetic pictographic system which means you have to straight up MEMORIZE four-thousand characters to be literate. Each character has anywhere from one to thirty-six strokes. EACH. As soon as I left high school and the pressure of grades to keep me absorbing and retaining, I promptly forgot everything. Everything, that is, except how to speak.
Fast forward a decade or so and I find my work has landed me back in China for the long haul. My spoken Chinese has picked up over the years but I’m still relatively illiterate. And as the use of cell phones and texting/chatting rises in China – even amongst my old masters – I’ve had to rely on a host of translation software to help me. The best (free) one so far is Google Translate.
I’d usually send a text to a master using Google Translate and when he wrote back, I’d ask a friend to read the Chinese out loud to me. Sometimes there were obvious miscommunications, but nothing we couldn’t solve with an actual phone call. It wasn’t until I started translating their texts and emails into English that I felt a sudden horrific awareness of the software’s limitations. I had been blindly putting my faith into this program to do the most important thing for me: communicate.

What?

And, what?
If that’s what computer translation had done to their words, what had I been saying to them?
Of course, somewhere in the back of our heads aren’t we all aware that translation isn’t perfect? Even the most bilingual translators in the world can’t produce an exact duplicate of meaning simply because languages aren’t just a sets of parallel words; it represents so many other possible differences such as culture, societal norms, emotional realities, histories, geography, political systems, ideologies, religions, etc. And even if we’re working in the same language, how can we ever be sure that what we say is what is exactly perceived on the other end? We can’t, because translation is so often a one-way street. Then why was I so shocked at my masters’ mangled texts?
For this week’s readings on glitch and deformance studies, I’ve chosen to fuck up/with Google Translate. To be sure, I’m not the only one who has been burned by the seductive promise of free translation. An estimated 200 million people are using Google Translate around the world every day[ii]. Do they know about Google Translate’s inherent incapabilities? Do they trust it blindly as I once did? Are they aware but still, like me, using it because of practical and financial reasons? What does this reliance on translation software mean in a greater context? It may mean that everyday, 200 million messages are being communicated incorrectly.
In Google Translate’s informational video, they explain how their translating program works:
Instead of trying to teach our computers all the rules of a language, we let our computers discover the rules for themselves. They do this by analyzing millions and millions of documents that have already been translated by analyzing millions and millions of documents that have already been translated by human translators. These translated texts come from books, organizations like the UN and websites from all around the world. Our computers scan these texts looking for statistically significant patterns – that is to say, patterns between the translation and the original text that are unlikely to occur by chance. Once the computer finds a pattern, it can use this pattern to translate similar texts in the future. When you repeat this process billions of times you end up with billions of patterns and one very smart computer program.
To me, this method exposes a host of issues, which the video does touch on but very very briefly. The ‘frequency of documents’ and therefore the quality of the translation depends on a number of variables; not just the preponderance of the language in question but language pairs as well. If the United States and China are trading more documents than say, Lithuania, then English to Mandarin translation will most likely fair better than English to Lithuanian. And, what kinds of documents are these? If many of them come from the UN as explained in the video, what kind of language patterns are most frequently found? What kind of language patterns are not found? How can we, the user, know what it does better or worse? How do we expose this system of its breakdowns and our expectations of perfection?
In Menkman’s manifesto on Glitch studies and Glitch art, she describes the glitch as having “no solid form or state through time; it is often perceived as an unexpected and abnormal modus operandi, a break from (one of) the many flows (of expectations) within a technological system”. (Menkman 341) The glitch is what exposes our unconscious expectation of a system: Neo’s déjà vu in The Matrix. I like that Menkman doesn’t see this as a negative thing entirely, but a catalyst for creation. “A negative feeling makes place for an intimate, personal experience of a machine (or program), a system exhibiting its formations, inner workings and flaws. As a holistic celebration rather than a particular perfection these ruins reveal a new opportunity to me, a spark of creative energy that indicates that something new is about to be created.”(341)
Jerome J. McGann and Lisa Samuels suggest a similar method to glitch art, but apply it to literary studies and call it Deformance. They argue that, “most ‘antithetical’ reading models operate in the same orbit as the critical practices they seek to revise: when critics and scholars offer to ‘read’, or reread, a poem, they hold out the promise of an interpretation.” (McGann & Samuels 2) Instead, they suggest subverting our methods of close reading and even anti-close reading by moving past interpretation altogether. They do this in the performative realm and suggest Emily Dickenson’s ‘reading backwards’ as a starting point. It’s a way to get us out of our ruts and into estrangement. It’s glitch theory as a theory. Instead of just reading my transfigured paragraph as a way to defamiliarize and expose our implicit trust of a system, they probably would have urged me to then analyze this new deformance as a work unto itself.
Mark Sample, however, has no desire to merge the performative and the deformed. Instead, he encourages us to leave it there, mangled, transfigured and deformed. He doesn’t “want to put Humpty Dumpty back together again.” And while he cites deformance as a move in the right direction, he believes the theory is actually just another derivative of our habitual ‘searching for meaning’ because, ultimately, it circles back to the original text or creation of meaning. In Sample’s deformed Humanities, “the deformed work is the end, not the means to an end.” Perhaps he’d like that initial nonsensical paragraph by Gaonkar and Povinelli the way it is.
So how do we glitch it? Fuck with it? Deform it and let it stay that way? Break the flow and disrupt our expectations? Well, we could do worse than to start here:
The Fresh Prince: Google Translated (Personal Fave)
Strange Pattern Glitches in the Program
As this week wore on and I began playing with Google Translate, experimenting on the quality of translation for certain languages and certain passages from different types of texts, it also became clear to me that perhaps Google Translate is a form of ‘reading backwards’ or deformance. There is a beauty in the estrangement with which we encounter our language again and can bring us new insights or understandings not only about the text but about language.
Take this ebook for example: 10 Poems Ruthlessly Mangled by Google Translate. The book simply takes ten poems and shows them in various states of transfiguration; one, two and three times through the translator. The intro states “some of the garbled poems are better then the originals. I don’t know how to feel about that.” (2) Or transfigured twice, “Good poetry twisted some more Original. I do not know how you feel about it.”
Selections from the ebook:


To me, all of these glitch art pieces and deformances do exactly what glitch studies promises. We are yanked into awareness by the hilarity, the unintended uses, the glitches. There is a beauty in the breakdown. To me, the most beautiful realization these methods and deformances show us is not only the fragility of a system, but of language, transfiguration and communication itself. We are our own imperfect translation computers impossibly slinging miscommunications everyday.
“Just as Foucault states that there can be no reason without madness, Gumbrecht wrote that order does not exist without chaos, and Virilio stated that technological progression cannot exist without its inherent accident. I am of the opinion that flow cannot be understood without interruption, or functioning without ‘glitching’. This is why we need glitch studies.” (Menkman, 344)
[i] Gaonkar, Dilip Parameshwar , and Elizabeth A. Povinelli. “Technologies of Public Forms: Circulation, Transfiguration, Recognition.” Public Culture 15.3 (2003):394
[ii] http://news.cnet.com/8301-1023_3-57585143-93/google-translate-now-serves-200-million-people-daily/
References:
Gaonkar, Dilip Parameshwar , and Elizabeth A. Povinelli. “Technologies of Public Forms: Circulation, Transfiguration, Recognition.” Public Culture 15.3 (2003): 385-397. Print.
Menkman, Rosa. “Glitch Studies Manifesto” Video Vortex reader II: moving images beyond YouTube. Amsterdam: Institute of Network Cultures, 2011. Print.
Shankland, Stephen. “Google Translate Now Serves 200 Million People Daily.” CNET. N.p., n.d. Web. 15 Nov. 2013. <http://news.cnet.com/8301-1023_3-57585143-93/google-translate-now-serves-200-million-people-daily/>.
Sample, Mark. “Notes Towards A Deformed Humanities” SAMPLE REALITY. N.p., n.d. Web. 15 Nov. 2013. <http://www.samplereality.com/2012/05/02/notes-towards-a-deformed-humanities/>.
“Informational Video.” Inside Google Translate Google. N.p., n.d. Web. 15 Nov. 2013. <http://translate.google.ca/about/>.
The post Google Translate: Glitch Art and Deformance Methods appeared first on &.
]]>The post Bootcamp: Our Humanities Theorists Tree-mapped appeared first on &.
]]>Bootcamp + Trees + Nov 7
“There is a constant branching-out, but the branches also grow together again, wholly or partially, all the time.” – Alfred Kroeber, Anthropology
Experiencing our class thus far, I must say it’s been less painful then expected to get my mind inside the theory circle. Once I became familiar with the ‘big names’ and most of the prevalent terms and ideas, everything became much easier. The circulatory nature of theory in the Humanities is evident as you read repeated names and quotes cited in each of our readings. And, as the semester has worn on, it has already become clear to me who speaks loudest to my sensitivities, my ways of working and my intuition. I have favorites: theorists I’ll keep tabs on and those I probably won’t. It’s the same for them. Some drool over Foucault while other go for Delueze and Guattari.
Franco Moretti had me at ‘graphs’.
This last series of Graphs, Maps, Trees is right up my alley because I am an intensely visual learner and communicator. Moretti gave us darn good reasons as to why this use of quantitative data and its visual representation add something to the textual humanities and can give us a new way of seeing. Of Graphs, Maps, Trees, I’m most interested in Trees. It probably has to do with my subject of study and its long lineage or my penchant for trees themselves. The graphs here feel less rigid, more organic and illustrate the more ‘messy’ bits of quantitative data better. Either way, I knew it was the perfect form for my latest question: the lineage of thought.
For this week’s Bootcamp, I’d like to experiment with our own syllabus. Who/what are we reading and what did those people read? How is the flow of theory/knowledge passed down to us and how do we become a part of it? Who inspired those who inspire me?
So, I made a tree graph.
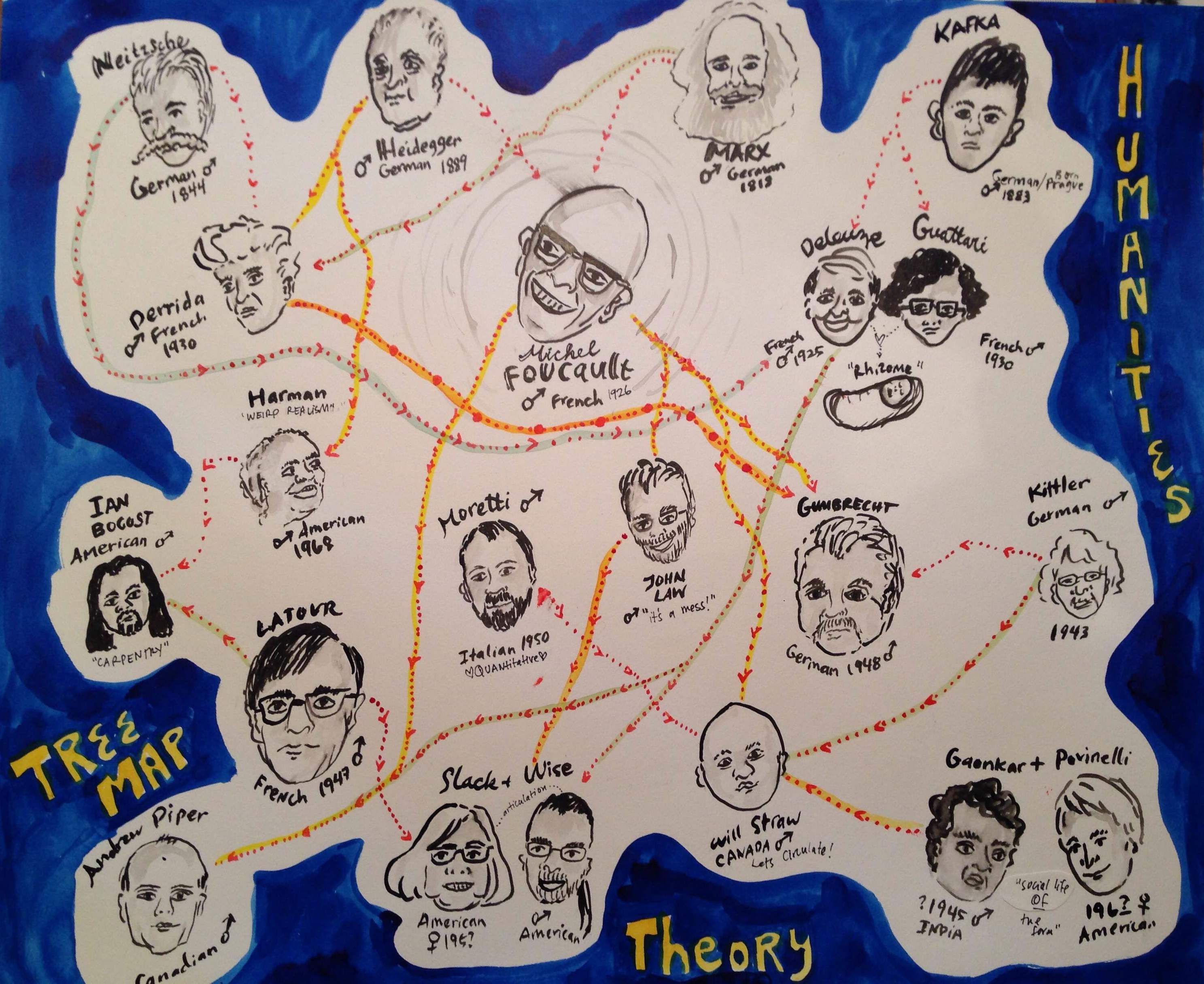
I chose to do this with my own artistic interpretation because 1) I’m horrible with computer programs, 2) It’s dead fun to cartoonize the serious theorists we’ve been reading*, 3) We can see how the cartographer’s bias can influence our interpretation of the information. My method was similar to Moretti’s method of plotting Hamlet in next week’s Network article: I went through all of the readings and marked down each writer’s direct positive references within the articles we’ve read. If there was no obvious citation, I went online and did a search to see who their biggest influences were. I, by no means, exhausted these articulations. Sadly, I had to make many omissions and simplifications in order to fit it on the page. JP Harvey’s Deconstructing the Map and its warnings about the cartographer’s inherent bias is well taken.
My initial plotting of the theorist tree:
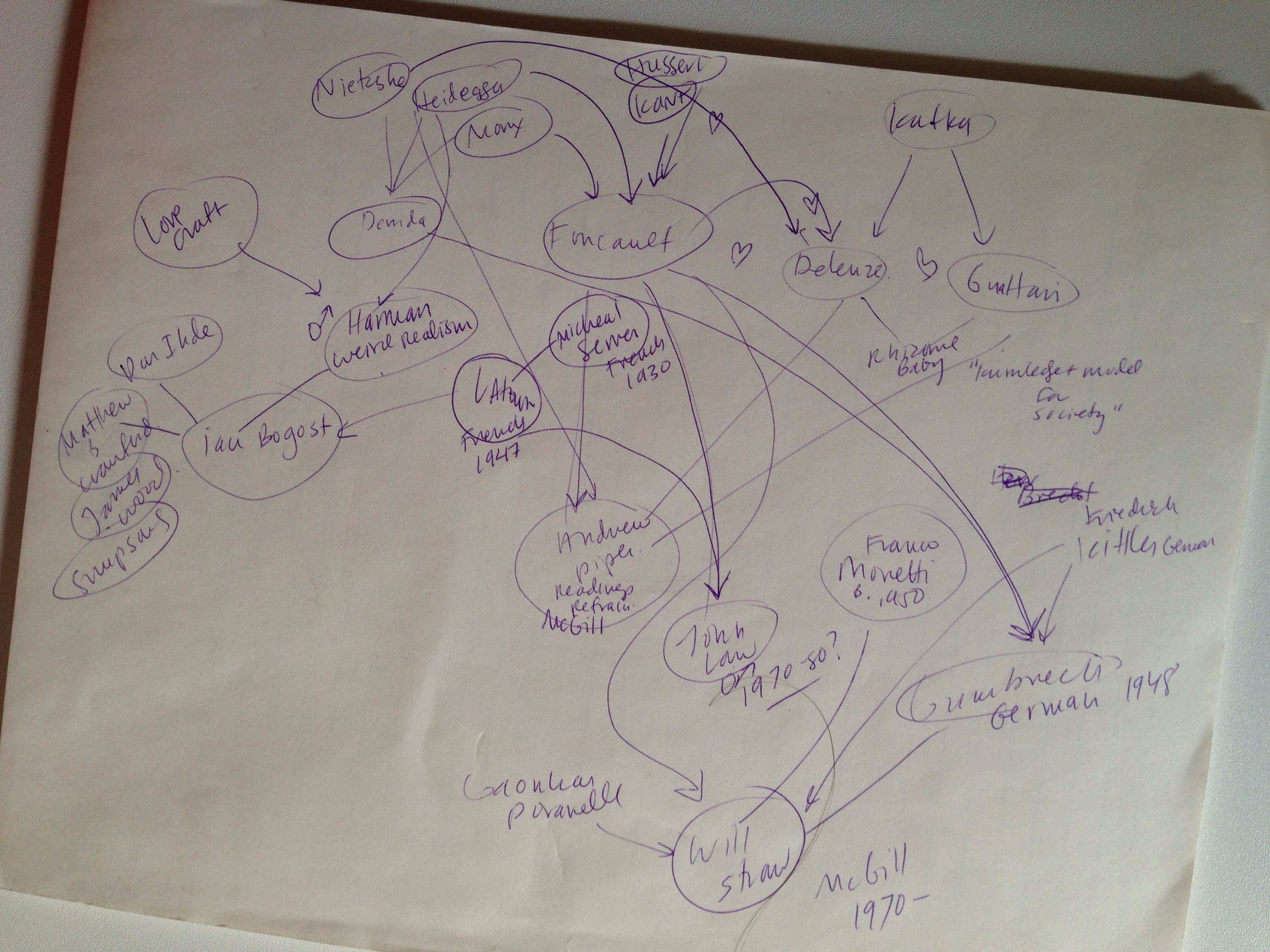
Although it looks like a network graph, it’s really a tree: I loosely placed them from oldest (top of the page) to youngest (bottom of page). And even though it’s messy – it actually does help me see things:
- If you want to be a theorist in the Humanities, you should probably grow a mustache.
- Foucault is by far the most referenced writer in our readings.
- There are other prominent authors that reference within the Humanities less but are referenced more (Moretti, Latour). Does this speak to writing style or more independent or interdisciplinary thought?
- If you do this long enough and are awesome at it, you will come to be referenced by last name only. Also, if you are in collaborative pair.
- Weirdly, there is little symbiotic sharing of intellectual love (other than the collaborative pairs). Most of this seems to simply be because of generational spans.
- At first glance, I thought: of course, it’s all a bunch of white guys from Germany and France. But if you look more closely at the ‘generations’ from top to bottom, you can see that even just in the last 50 years, the field has become much more diverse. I’m not sure if this speaks to the field at large or if Darren has just done a good job of making a point to include these scholars.
To place myself within the spaghetti dinner of thought, I’d probably plop myself down right below Moretti, John Law and Slack and Wise. I feel comfortable there in all directions: Mess, visual representations the present new information to the humanities and Articulations and Assemblages. Interestingly, these scholars are inspired by some of the others that I simply can’t get into – but now, seeing the lineage, feel closer to.
What do you see? Can you see anything at all? Does it help to clarify things or just confuse you? What does humor do to the information? Where are your pathways?
*Making Foucault look like the evil mastermind in the middle was a bit of an accident. Or was it?
And, just for fun, the winning mustache goes to: Nietzsche.

The winning overall hairstyle: Marx.

References:
Goodwin, Jonathan, and John Holbo. Reading Graphs, maps & trees: responses to Franco Moretti. Anderson, SC: Parlor Press, 2011. Print.
Harley, J. B., and Paul Laxton. The new nature of maps: essays in the history of cartography. Baltimore, Md.: Johns Hopkins University Press, 2001. Print.
Moretti, Franco. Graphs, maps, trees: abstract models for a literary history. London: Verso, 2005. Print.
The post Bootcamp: Our Humanities Theorists Tree-mapped appeared first on &.
]]>
Order on Order (the story, the map, the disturbing landscape of…)
(bootcamp: the markdown)
.
The map in Lewis Carol’s Hunting of the Snark is a blank. Yet they make it to the island (what is an island defined by a blank map?). Order in the Hunting of the Snark is a series of absurdities-as-rules brought about by the author, including the narrative itself which could be summarized as follows:
THE LANDING > THE VANISHING
Its sad this, but less sad than it would be without the humour of order, without lyric and narrative jest layered like the smooth membrane of a page (as a map of time) over nothingness and the inevitable (if a narrative ‘inevitable’ is not already a map of time). This “agony in eight fits” begins when the omniscient (or so the crew is lead to believe) Bellman lands his crew with care,
“Just the place for a Snark!” the Bellman cried, as he landed his crew with care; Supporting each man on the top of the tide by a finger entwined in his hair.
If we keep to the story, if we abide by the rules of this map, we will be safe, held gently above the abyss. We will be carried along with pleasure… to the end, far off in the future. It is a story for children.
My own copy of this epic quest (I think it was one of the first books I owned—it is definitely the book I have owned for the longest) is one illustrated by Mervyn Peake. I only discover today as I format this probe that the original (1884) illustrations were by Henry Holiday. We can compare the Bellman (Holiday -left; Peake-right):


Funny though, I thought the Bellman supported his people with a finger entwined in his own hair, not their hair! Needless to say I see the Holiday illustrations as latecomers, as wrong. The Peake illustrations were always ominous and disturbing for me. I owned this book before I could read. So the form of this book with its strange typography filled with quotation marks always fascinated me. Likewise, the two-handed mathematical calculations of the Butcher demonstrating how many times he said something while the Beaver looks on, deeply worried, were also a strange field of glyphs for me. This little book still resonates with this disturbing encounter with (incomprehensible) language and numbers. It is a feeling I still often feel when an external narrative of order or methodology presents itself.
On the cover of my copy of the hunting the title and author’s name is underlined in brown crayon (by me, I know). Inside the cover is the inscription ottwo.5 in the same brown crayon. Beside it, in my mother’s handwriting is my name and address. ottwo, if you can’t guess, is Ottawa. I do remember getting my mother to complete the inscription which marked my ownership of this little book. After I learned to read I was embarassed by the clumsy writing and mis-spelling. I’ve gotten over this.
Back to the map. I have spent most of my life without a tangible reference for the geography of the Hunting of the Snark. Fortunately, now I see images of the original 1884 illustrations which include Holiday’s very precise rendition of the map. It is a blank, a perfect blank, but one (to my dismay) framed by references to what lies haphazardly beyond this frame.

]]>
The post Selling Ideology and Crafting Constellations: Technological Culture and the Museum of Me appeared first on &.
]]>Perhaps one of the best ways to visualize the concepts of articulation and assemblage from for this week’s seminar, ‘Drawing Things Together,’ is the process of learning: by making associations and parallels between complex elements and familiar and/or simpler concepts, we are crafting and superimposing patterns that enable us to understand what appears to be foreign, new, and/or complex elements, thus ultimately gaining knowledge. As students, we spend many hours reading, writing, and discussing an array of different topics and theories, thus drawing links that are “not necessary, determined, absolute and essential for all time” (Grossberg 53) in our works, thus creating a “web of articulations” (Slack, Daryl, and Wise, Daryl, and Wise 112) in our head. Then the process of articulation and assemblage—or actor-network theory—becomes particularly relevant in terms of conducting research, considering that the works of a scholar is set in a contingent place within shifting webs of institutionalized, marginalized, and/or soon-to-be institutionalized theories.
When one goes looking for constellations, one can get lost among the stars; the multiplicity and scale of assemblages can be overwhelming. I was lucky enough, however, to stumble on a software that not only assembles my virtual social network for me, but also allows me to visualize it. This software is called ‘Museum of Me’, and this link will lead you right to it. For the purpose of my argumentation, I would encourage you to jump right in, and experience it yourself (by entering your own Facebook login), instead of viewing this generic rendition of the ‘Museum of Me’:
The impact of this ‘museum exhibit’ is of course stronger if you experience seeing your own friends and family, plus reading your own words and likes in this virtual gallery. The reason for choosing this software becomes obvious towards the end of the exhibit: robots are shown selecting and ordering the profile pictures of your friends and family into a canvas that ultimately depicts your own profile picture, which then reveals how you are linked to a web of people via your social network.
What better image to depict the concepts of articulation and assemblage as it relates to technology? (Either this is a rhetorical question or I’m challenging you to submit other examples in the comments). The ‘Museum of Me’ gathers from your Facebook account a multitude of information, but ultimately exhibit a very particular kind of elements about you (not just mere facts such as your age, profession, education); the gallery aims to show how your social interactions (on Facebook) define your (online) social identity. This ‘Museum of Me’ does not show much about yourself, but instead draws the contours of your social networks in order to reveal—much like with the canvas of your friends’ profile pictures—how your social identity is shaped by the people you interact with online. Thus this software “could be said to territorialize the articulations of…angles of relationships, space, atmospheric conditions, trajectories of movement, and a way of seeing,” thus becoming “in a sense, a contingent invention, both artificial and natural” (Slack, Daryl, and Wise, Daryl, and Wise 129, their emphasis). Every time you update certain elements in your Facebook account (a new friend, like, comment), you are eradicating the virtual exhibit that you have seen in the past—thus proving the contingency of the exhibit. By visualizing how you fit in a pattern of social networks, you see the territory that you occupy virtually and socially, thus envisioning a space that is ‘both artificial and natural’. Thus, just as a constellation “is made up of imaginative, contingent, articulations among myriad heterogeneous elements” (Slack, Daryl, and Wise 129) so is your own exhibit. The ‘Museum of Me’ reflects how “particular collection of (moving) bodies is articulated to a particular image” (Slack, Daryl, and Wise 129) by turning the profile pictures of your friends into your own, an image that is in fact a composite of social interactions and relationships that are in constant mutation.
So the ‘Museum of Me,’ what is it good for? (Don’t sing out, ‘absolutely nothing’ just yet). What is it about a museum exhibit that appears to be appropriate for representing a social network that is experienced virtually, which is both ‘artificial and natural’? Before jumping into discussing Intel’s agenda for producing such software (Justin McGuirk in his article in the Guardian does mention “brand awareness” as one of the reasons), let’s probe at the choice of a museum exhibit to represent one’s social interactions online. The interactions and elements selected by the ‘Museum of Me’ as mentioned earlier are not matters of fact, but are instead linked to a cultural dimension. The authors Slack, Daryl, and Wise define culture as being “understood to consist of corresponding, noncorresponding, and even contradictory practices, representations, experiences, and affects…not refer to effects, as in the outcome of a causal process, but to affects as a state: as disposition, tendency, emotion, and intensity” (Slack, Daryl, and Wise127). Considering the role of affects in the definition of culture, it becomes obvious that our social interactions online (even more directly with the ‘like’ button on Facebook) have a cultural component.

In the case presentation of the ‘Museum of Me,’ its creators mention that “we created a new form of storytelling” (around 20 seconds in). Here we seem to be touching something. If our social interactions online have a cultural dimension, and that culture is defined by affects rather than effects, then creating a ‘storytelling’ of that which is without causality becomes interesting. Picture the ‘Museum of Me’ thus as a narrative without a beginning nor an end, without plotlines or characters’ arches, but pure exploration of networks of affects, emotions, tendency, and intensity.
To create a narrative without causality and/or plotlines necessarily implies ruptures, breaks, and inconsistencies from the lack of a linear structure. This is particularly relevant for scholars who must situate their works in a history of theories and events that is not linear; how should we structure and order what is intertwined with culture—with affects and tendency, with emotions? How should we situate and present our work, which is always influenced to some degree by the culture we have internalized? While I have no answers, these questions could be informed by exploring the ‘form of storytelling’ that takes place in a museum—or in this case the virtual one.
Let’s consider how museums ‘communicate’ to its audience certain kind of information. According to Peter Walsh, museums have “traditionally ignored an important aspect of communication: that communication is not a monologue, but a dialogue,” (Walsh 234) and as such “Museums are almost unique among educational institutions in that they still are using a one-sided method of communication” (Walsh 234). This lack of reciprocity produces a certain kind of power, enabling the institution to impose a vision/structure into a firm one-sided discussion with its viewers—and students/scholars. Maria Roussou argues for this conversation to include its viewers by allowing them to directly communicate with the museum through the use of technology. This presents a perfect case of “technological culture” (Grossberg 128, his emphasis) that allow us to understand better the foundations of the ‘Museum of Me,’ as it directly uses technology and bypasses the institution itself. Roussou argues for the need of interactivity in museums, which she defines as the “reciprocal action…to act on each other, to act together or toward others or with others. Reciprocity can takes place between people, people and machines, people and software, or even machines and machines” (Roussou 249). This interaction is not only “seen as an intrinsic feature of educational practice” but also as “an inherent property of any interactive multimedia or virtual reality environment that promises physical and sensory, in addition to mental, activity and response,” which characterizes “learning as a process of making meaning through personally constructed or socially co-constructed knowledge (Jonassen 2000)” (Roussou 249). The use of technology hence branches out onto our ability as humans to interact with our environment—in this case archeological objects and/or works of art—in order to understand and learn from it. In the ‘Museum of Me,’ there is no direct interaction possible between the viewer and the exhibit itself, and this is essential to understand the purpose behind creating this institution as a format.
Why is it a museum of me? As an institution, museums thus refer to a historically “particular formation, anchored very directly in relation to a number of different forces,” (Grossberg 54) hence the museum’s “meaning—political and ideological—comes precisely from its position within a formation” (Grossberg 54). As discussed, museums are in a relation of power with its audience in the way they communicate the cultural objects that they have ordered. The discourse of a museum exhbit seum exhbit ibit hence might allow for a better control over the kind of ideology that is articulated by the use of this formation/structure. The ‘Museum of Me’ could hence re-conceptualize the non-interactive, one-sided, ideological, and authoritative elements of the museum discourse into a site of advertisement.
McGuirk in the Guardian depicts the ‘Museum of Me’ as “Entering this generically deconstructivist, what you get is a fly-through animation of a series of galleries, with pictures of you and your friends on the walls,” which ends with “a final sequence that implies, erroneously, that you are merely a composite of your social network. A soaring soundtrack turns the sentimentality dial to max” (McGuirk). Whether the implied message—or ideology—of the ‘Museum of Me’ is valid or not, what is relevant is that McGuirk pointed out that this experience started in a ‘deconstructivist’ building. If one considers the creators’ aim to craft a ‘new form of storytelling’ via the ‘Museum of Me,’ then this deconstructivist element becomes important. I believe the roots of the answer for, ‘why is it a museum exhibit’ are located there. Deconstructivism is a particular type of architecture that was inspired by the postmodern theory of ‘deconstruction’ as a semiotic analysis; it is characterized by its manipulation of surfaces in shapes that distorts typical rectangular structures and/or celebrate fragmentation. The very building that we enter in the ‘Museum of Me’ thus reflects a postmodernist vision, which articulates ‘fragments’ of ‘me’ into assemblages of social interactions on Facebook. Just like in Hall’s example of the postmodernist experience, the ‘Museum of Me’ “contains emergent ‘postmodernist’ elements, as it were, is that there is no story in the old sense,” ‘me’ does not “come from anywhere; there is no whole story about him to tell” (Grossberg 47).
By looking at the very space used for a museum exhibit—its externality—one can understand how the inevitable ruptures and breaks (inherent in the postmodern view of way) within a narrative of cultural elements (of affects) are negotiated. The ruptures are always present in a museum exhibit, but have been institutionalised; the walls represent specific artists with similar affects, and the different rooms represent different ‘ages,’ movements, or centuries. When one moves from room to room, and from wall to wall, one is navigating the both the instituted linearity (the museum’s ordering structure, such as the walls and rooms) and its ruptures (the empty space between paintings, the middle of room, the staircase between two rooms of the same exhibit) at once. What the ‘Museum of Me’ does is exactly that; by using institutionalised structures (representing virtually the rooms and walls of a museum exhibit), this software allows for a narrative displaying assemblages (your friends in one room, your likes in another) while making you unaware of the gaps and inconsistencies in its ordering. Perhaps Latour’s third criteria as the ‘Power to Arrange in Bank Order’ which specifically relates to the ‘notion of value’ can add another layer of interactions as to what the ‘Museum of Me’ does. As such, we shall briefly—unfortunately too briefly—mention “the compatibility of new propositions with those which are already instituted” (Latour 109) such as Intel’s re-conceptualization of museums befitting the ‘new’ way to communicate, and advertise ideology.
This was one small instance of an institution such as museums beings re-conceptualised to sell us an ideology—and of course the product behind it. To link this discussion to our work and research, how can we use these theories of assemblages to form the networks necessary for our work to be circulated, instead of being marginalized by what is institutionalized, contingently relevant, and/or what the majority engages with? This discussion had for goal to make us indirectly reflect on the selling and spreading of an ideology, which as consumers and scholars, we participate to. Are we not indeed attempting to selling an ideology whenever we look for funding or publication?
Works Cited
Latour, Bruno. “A New Separation of Powers.” Politics of Nature: How to bring the Sciences into Democracy. Cambridge: Harvard University Press, 2004. 91-127. Print
Grossberg, Lawrence. “On Postmodernism and Articulation: An Interview with Stuart Hall.” Journal of Communication Inquiry 10(1986): 45-60. Print
McGuirk, Justin. “Robot Cleaners and the Museum of Me: Intel’s Vision of the Future.” The Guardian. Tues 24 Jan. 2012. Web.
Roussou, Maria. “Learning by Doing and Learning through Play: an Exploration of Interactivity in Virtual Environments for Children.” Museums in a Digital Age. By Ross Parry. London: Routledge, 2010. 247-265. Print
Slack, Daryl, and Wise, Jennifer Daryl, and J. Macgregor Wise. “Causality,” “Agency,” “Articulation and Assemblage.” Culture +Technology: A Primer. New York: Peter Lang, 2005. 101-33. Print
The post Selling Ideology and Crafting Constellations: Technological Culture and the Museum of Me appeared first on &.
]]>The post The Viewers’ Remixes & Supercuts: (Re)Ordering Content and/or Mess appeared first on &.
]]>
Mess is inevitable: it is in our thought-process, our social interactions, our work, our mistakes and accomplishments, but most importantly it is also there in the creative process. When looking for supercuts on the internet, this website leads you to an archive of supercuts, which provides a definition for them:
Supercut: noun \ˈsü-pər-kət\ — A fast-paced montage of short video clips that obsessively isolates a single element from its source, usually a word, phrase, or cliché from film and TV. Supercut.org collects every known example of the video remix meme.
This ‘obsession’ creates a framework, a sort of viewer’s critique that highlights how this single element is repeated (and thus circulates) throughout a variety of different circumstances, events, or sources. For example, by isolating a sentence from the Wizard of Oz movie the following supercut shows how a single element can spread and circulate in a series of different contexts (networks) to ultimately become a popular culture reference:
Supercut of a Line from the Wizard of Oz
Simon Owens who writes about the impact of supercuts in the shape of nostalgia gives numbers to the general amount of editing in one single supercut, mentioning that in “2011, Baio analyzed a database of over 146 supercut videos and found that ‘the average supercut is composed of about 82 cuts, with more than 100 clips in about 25 percent of the videos’” (Owens). The extensive editorial effort provided by the creators of supercuts points to the difficulty of finding ways to order what must first appears to be a messy pile of data.
As an aspiring scholar myself, I found their creative—and yet—rigorous method intriguing enough to dig a little deeper. Could supercuts make visible the network patterns that John Law describes as running “wide and deep – that they are much more generally performed than others” (Law 385), thus illustrating how “network patterns that are widely performed are often those that can be punctualized…because they are network packages – routines – that can, if precariously, be more or less taken for granted in the process of heterogeneous engineering” (Law 385, his emphasis). Considering how supercuts create “a kind of ‘Aha!’ moment when a Hollywood cliché that you perhaps never fully internalized is laid out for you” (Owens), I would argue that they are disrupting force—perhaps even (when shared and spread) a resistance—to the sort of formulaic engineering of inserting certain overused tropes (or references) within the content of a film or series. Why would the phrase from the Wizard of Oz be used so many times? The actor-network theory might explain it in part. By alluding to the Wizard of Oz, the writers are making a reference to something that is familiar to a vast number of people, and thus this phrase becomes an actor in a grander scope of networks (viewers). This phrase has the power to connect the writers’ content to a complex spectrum of effects spreading from nostalgia to comedy.
Since supercuts isolate elements that could have been lost in a sea of content (massive amounts of unseen and/or unrelated movies and/ or television shows), could supercuts also be, in way, a punctualization? While the digitalisation of television and cinematographic content aids the phenomenon of supercuts, “these forms can be traced back to pre-digital technologies of the 1970s (in the case of Penley’s Star Trek fan videos) or the pre-YouTube and Web 2.0 participatory sharing (in the case of Cover’s Buffy the Vampire Slayer fan videos, distributed through newslists, email and private website)” (Cover). By now being able to ‘binge-watch’ a whole series (which can sometimes amount to eight or nine seasons of twenty plus episodes) due to the digitalisation of content, viewers of such content appear to have new ready tools to engage with, share, and modify massive amounts of data.
Rob Cover argues that despite this blossoming of digital methods and tools, “there has emerged a methodological gap requiring new frameworks for researching and analysing the remix text as a text, and within the context of its interactivity, intertextuality, layering and the ways in which these together reconfigure existing narratives and produce new narrative” (Cover). The way supercuts organize and order their content could be an example of how massive amounts of content could be framed in order to highlight the interactivity and intertextuality of their content.
The ‘methodological gap’ to research and analyze the remixes (and/or supercuts) that Cover points out is not unlike the one that fostered Law’s interest “in rehabilitating parts of the mess” (Law 4). Hence by trying to find frameworks in order to include (and assign meaning) viewers’ and/or fan-based’ works, we are simultaneously trying to imagine new ways to include messy bits into our methodology. The inclusion of those types of media in research is particularly relevant to Lawrence Lessig, who argues that text “is today’s Latin,” since it is “through text that we elites communicate…For the masses, however, most information is gathered through other forms of media: TV, film, music, and music video. These forms of ‘writing’ are the vernacular of today,” and ultimately adds that for “anyone who has lived in our era, a mix of images and sounds makes its point far more powerfully than any eight- hundred- word essay in the New York Times could” (Lessig 68-69). To illustrate the potential repercussions of combining arguments with media, follow through this experiment: would this clip demonstrating how a character manipulates individuals with pop culture references to create a ‘community’ reinforce Law’s argument that “our communication with one another is mediated by a network of objects – the computer, the paper, the printing press….that these various networks participate in the social. They shape it” (Law 382)?
Short Clip from Pilot Episode of the TV Show Community
Also, could this type media thus be used not only to shape our social networks and interactions, but also to “overcome your reluctance to read [Law’s] text” by reinforcing “the social relationship between author and reader” (Law 382)? Could then supercuts be considered as the product of a distant reading, and if they are, could they represent a different media (other than writing) to reveal patterns and networks between non-obvious elements? Most importantly for my case, would considering this media as a potential way to enlarge or enrich our methodology enable us to tackle down more complex and messier concepts?
Consider the complexities that arise in an episode from the TV show Community entitled “Remedial Chaos Theory” in which the interactions between the characters diverge and/or converge when a person must leave the room to go get pizza.

They roll a die to determine who gets to leave the room, and this sequence is repeated to show each of the seven plausible (and very different) storylines contained in this episode. A supercut would make a montage of the repetitive sequences, namely the rolling of the die, and discard the variants. However, take a look at another type of fan-based/viewers clips that was created, and reminisce Law’s leading question, “‘would something less messy make a mess of describing [mess]’” (Law 4):
Juxtaposition of Content rather than a Supercut
This clip—and other similar ones–cannot be called supercuts since they did not in fact isolate repetition. They created instead a patchwork that allows the viewers to notice all the repetitions while viewing all its parallel differences. These clips could also represent the compilation of data before the massive editing (such as in supercuts or essays): before discarding the bits that do not fit to seek a pure pattern, a seemingly complete repetition. These clips are messy, noisy, heterogeneous, and relevant, “because that is the way the largest part of the world is” (Law 4). The reluctance to order something that is already complex, the surviving mess in those clips points to Law’s argument that “Clarity doesn’t help. Disciplined lack of clarity, that may be what we need” (Law 4). By not adhering to a massive edits (but instead minor ones, to juxtapose the storylines), these clips thus show a much more complex and richer patchwork of parallels, repetitions and variants.
These clips “broaden method” (Law 4), by not ‘obsessing’ with “clarity, with specificity, and with the definite” (Law 4). These clips can be used as a parallel for the moment when someone conducting research is facing a multiplicity of data converging and diverging in places, noisy and messy at times but also repetitive and similar at others. Should we then attempt to ‘Other’ “Everything that doesn’t fit the standard package of common-sense realism…Everything that is not independent, prior, definite and singular” (Law 8)? Or should we attempt to use this mess as the creators of those clips did, to better understand its source? How can we understand the complexities of mess if we can only use methods that ultimately order—and thus alter—it?
Works Cited
Lessig, Lawrence. Remix: Making Art and Commerce Thrive in the Hybrid Economy. New York: Penguin, 2008. Web.
Law, John. “Notes on the Theory of the Actor Network: Ordering, Strategy and Heterogeneity.” Lancaster: The Centre for Science Studies, Lancaster University, 1999. Revised 2003. http://www.comp.lancs.ac.uk/sociology/papers/Law-Notes-on-ANT.pdf
–. “Making a Mess with Method.” Lancaster: The Centre for Science Studies, Lancaster University, 2003.
http://www.comp.lancs.ac.uk/sociology/papers/Law-Making-a-Mess-with-Method.pdf
Owens, Simon. “How the Supercut Changed the Shape of Nostalgia.” DailyDot. 23 August 2013. 12 September 2013.Web.
http://www.dailydot.com/entertainment/supercut-nostalgia-history-slacktory/
Cover, Rob. “Reading the Remix: Methods for Researching and Analysing the Interactive Textuality of Remix.” M/C Journal 16.4 (Aug. 2013). 12 Sepember 2013. Web.
http://journal.media-culture.org.au/index.php/mcjournal/article/view/686
The post The Viewers’ Remixes & Supercuts: (Re)Ordering Content and/or Mess appeared first on &.
]]>